[SQL] Group By와 Having
[SQL] Group By와 Having
서론
이곳저곳 면접 질문들을 찾아보면 빠질 수 없는 SQL 질문 중 하나가 바로 Group By와 Having의 응용이다.
따라서 이에 대한 개념을 확실히 잡고자 실제 쿼리를 작성해보면서 포스팅해볼 예정이다.
Group By란?
같은 값을 가진 행을 그룹화하는 SQL 명령어이다.
이는 보통 집계 함수를 사용하기 위한 목적으로 사용된다.
또한 각 그룹의 하나만을 반환하기에 중복을 제거하는 기능도 존재한다.
Distinct vs Group By
Distinct는 컬럼 내 데이터의 중복을 제거하여 조회하는 반면, Group By는 컬럼 내 데이터를 Unique한 값을 기준으로 조회한다.
쉽게 말해, Distinct에 정렬이 추가된 명령어가 Group By라고 볼 수 있다.
집계 함수
- Count() : 그룹의 갯수 반환
- Max() : 그룹의 최댓값 반환
- Min() : 그룹의 최솟값 반환
- Sum() : 그룹의 합계 반환
- Avg() : 그룹의 평균 반환
예제
테이블의 데이터가 다음과 같이 있다고 치자.
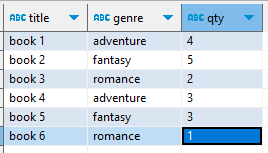
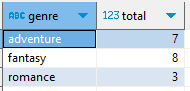
이때, 장르별 책의 갯수를 구하고자 한다면 쿼리는 다음과 같이 작성될 수 있다.
먼저 장르와 갯수의 합을 조회하기 위해 genre, sum(qty)를 Select한다. 또한, 칼럼을 그룹화하고 집계 함수를 사용하기 위해 장르를 기준으로 Group By를 진행하면?
1
SELECT genre, sum(qty) AS total FROM book Group By genre;
Having
Having은 그룹에 대한 조건을 명시하는 키워드로, Group By에 의해 그룹화된 행에 조건을 부여한다.
1
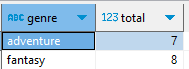
SELECT genre, sum(qty) AS total FROM book Group By genre HAVING total > 5;
total이 5보다 큰 행들을 조회하도록 조건을 걸어보면 다음과 같은 결과를 얻을 수 있게 된다.
This post is licensed under CC BY 4.0 by the author.